
A build oversight, possibly made worse by a known bug in Bun, the JavaScript runtime Anthropic acquired, that serves source maps in production regardless of config.
The internet mirrored it within hours. Inside that codebase is a detailed record of what it looks like to run an AI coding agent at scale: what breaks, what you patch, and how you think about it.
The @[MODEL LAUNCH] tags, the circuit breakers with their exact failure counts, the cache-break incident logs: these are scars. Someone earned each one in production. Most of what I found, you can use today. The specific numbers throughout this piece come directly from code comments and variable names in the source.
Your system prompt is an engineering document
The most valuable file in the leak isn’t a clever algorithm. It’s constants/prompts.ts — the full system prompt for Claude Code.
Throughout the file you’ll find comments tagged @[MODEL LAUNCH]. These are workarounds for specific model-generation failure modes, explicitly labeled so the team knows to revisit them when the model updates. One example: “Default to writing no comments” — added because the current internal model family over-comments by default. Another: “Report outcomes faithfully. Never claim all tests pass when output shows failures.” Added because newer model versions have a measurably higher false-claims rate than older ones. The annotation tells you which model version introduced the problem and what the rate is. That’s an engineering log, not a prompt.
More capable models are more likely to confidently paper over failures. They’re better at generating plausible summaries, which means they’re better at hiding broken results. “Be honest” in your prompt isn’t enough. You need to name the specific failure mode: don’t claim passing tests when output shows failures, don’t characterize incomplete work as done.
One more thing from the prompt: numeric length anchors beat qualitative instructions. Their internal comment says ≤25 words between tool calls produces about 1.2% fewer output tokens than “be concise.” Stop using adjectives to control output length. Use numbers.
There’s also an external vs. internal prompt split. The version shipped to regular users says “go straight to the point, be extra concise.” The version Anthropic employees get is significantly richer — instructions like “use inverted pyramid,” “avoid semantic backtracking,” “write so the reader can pick back up cold.” They dogfood the more ambitious version internally, measure quality, and promote it externally once the data supports it. That’s a prompt iteration strategy worth copying.
Finally: CLAUDE_CODE_SIMPLE=1. Set that environment variable and the entire multi-section system prompt collapses to a single line, “You are Claude Code, Anthropic’s official CLI for Claude”, followed by the working directory and date. No coding rules, no tone guidance, no tool-use instructions. It exists for debugging and benchmarking. When something goes wrong, you need to isolate whether the problem is in the model or in your prompt. A one-line baseline lets you test that immediately. If your product has a complex system prompt, build yourself a SIMPLE mode. You’ll need it the first time your prompt causes a regression you can’t explain.
Agents cannot audit themselves
When Claude Code makes non-trivial changes — three or more file edits, any backend or API changes, infrastructure modifications — a separate sub-agent with subagent_type=”verification” is spawned automatically. It receives the original request, all changed files, and the approach taken. The constraint is explicit: the actor cannot self-assign PASS. Only the verifier can.
Here’s how the multi-agent coordinator wires this together in practice:
After the verifier issues a PASS, the original agent is instructed to spot-check the verifier’s evidence — re-run two or three commands from its report, confirm every PASS has actual command output. Nobody trusts anybody without proof.
The actor cannot self-assign PASS. Evidence requirements before the verdict stands.
A cache miss is a billing event
promptCacheBreakDetection.ts tracks 14 separate components that can invalidate a prompt cache: system prompt, every tool schema individually, model name, beta headers, fast-mode state, effort value, overage state, and more. On every API call, each is hashed and compared against the previous call. When something changes, the diff is logged.
Why does this exist? Because a cache miss means paying full input token cost instead of the discounted cache-read rate. The source reveals specific incidents: MCP (Model Context Protocol) tools connecting mid-session, auto-mode state flips, and overage eligibility checks were all busting the cache. Each got patched with sticky-on latches: once a state flips to true, it stays true for the session so the cache prefix never changes.
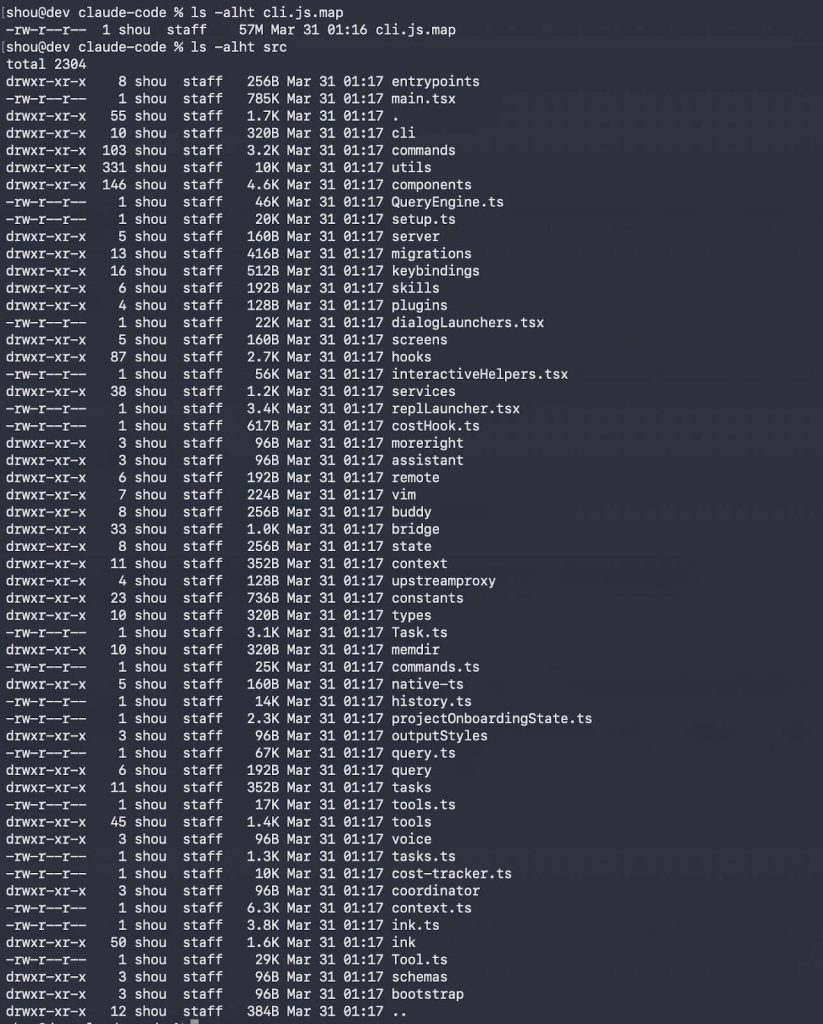
They also discovered a session failure bug burning 250,000 API calls per day. A comment in the code documents it precisely: “1,279 sessions had 50+ consecutive failures (up to 3,272) in a single session.”
The fix was a circuit breaker: MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3. The compaction system also has battle-tested thresholds worth using directly: 20,000 token reserve for summary output, 13,000 token buffer before auto-compact triggers, 3,000 token buffer before the user is forced to compact.
If you’re spending real money on LLM APIs, build cache break detection. Hash your request components. Log when something changes. You will find timestamps, user names, or dynamic tool lists sitting inside your “static” prompt, silently multiplying your costs every session.
Regex outperformed the LLM here
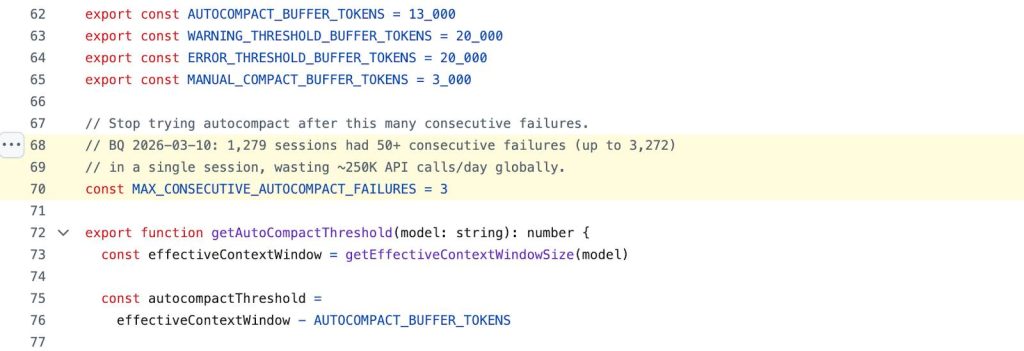
Anthropic built a frustration detector. It checks every user prompt against a regex list of negative keywords before the message is sent to the API. When it matches, it logs is_negative: true to analytics alongside model version, latency, and session characteristics. There’s a separate is_keep_going flag for prompts that are just ‘continue’ or ‘keep going’.
Twenty-six lines of code, no inference call, no model involved.
This is the same company that built one of the most capable LLMs in the world. They use regex to measure user satisfaction. The lesson isn’t specific to sentiment detection: ‘use AI for everything’ is a philosophy, not an engineering principle. Every inference call has latency and cost. When a simpler tool solves the problem cleanly, use it.
Production memory has a schema. Use it.
autoDream.ts implements background memory consolidation. After enough sessions accumulate, a forked sub-agent reviews past transcripts and writes structured MEMORY.md files. The extraction template has ten categories: Session Title, Current State, Task Specification, Files and Functions, Workflow, Errors and Corrections, Codebase Documentation, Learnings, Key Results, and Worklog. Each section capped at around 2,000 tokens, total at 12,000.
The gate order runs cheapest checks first: has enough time passed, have enough sessions accumulated, is another process already consolidating. If consolidation fails, it rolls back. Memory extraction re-triggers every 5,000 context tokens or 3 tool calls after the initial 10,000-token threshold.
Here’s the KAIROS autonomous agent mode, the unreleased always-on system that this memory infrastructure is designed to serve:
If you’re building any agent that needs context across sessions, that’s a production-tested schema. The thresholds come from a system running at serious scale, not from theory.
Your build pipeline is an attack surface
bashSecurity.ts is 2,592 lines with 42 distinct checks for attack vectors in shell command execution. Some are niche enough that most security engineers haven’t considered them. The Zsh-specific ones are worth noting in particular: Zsh equals expansion (=curl evil.com bypasses Bash deny rules because the parser sees =curl as the base command) and zsh/net/tcp enabling network exfiltration via ztcp are both real attack paths that most security tooling misses entirely, because most security tooling focuses on Bash.
Zsh is the default shell on macOS. If you’re building anything that executes shell commands from LLM output, that file is your checklist.
There’s also a client-side secret scanner in teamMemorySync/secretScanner.ts that runs before any team memory is uploaded. It checks for 20+ credential patterns: AWS access tokens, GCP API keys, GitHub PATs, Anthropic API keys, Slack tokens, Stripe keys, private RSA and SSH keys. The Anthropic API key regex is deliberately split across variables so sk-ant-api03- never appears as a string literal in the bundle. Scan before upload, never after.
And there’s a post-build canary: excluded-strings.txt lists internal codenames and strings that must never appear in the external build. The build system greps the bundle and fails if any are found. That’s why certain strings in the codebase are assembled with .join(‘-‘) at runtime or encoded as String.fromCharCode() instead of plain literals: to survive the grep. Species names in the companion system are all hex-encoded uniformly, even the harmless ones, so the one that collides with an internal model codename doesn’t stand out.
The irony: this exact mechanism was designed to prevent leaks. The leak happened through a source map that bypassed it entirely. The pattern is still sound. The one vector you don’t check is the one that gets you.
How to poison your own training data, on purpose
services/api/claude.ts contains a feature-flagged measure that sends anti_distillation: [‘fake_tools’] in the API request body, instructing the backend to inject fake, non-functional tool definitions into the prompt.
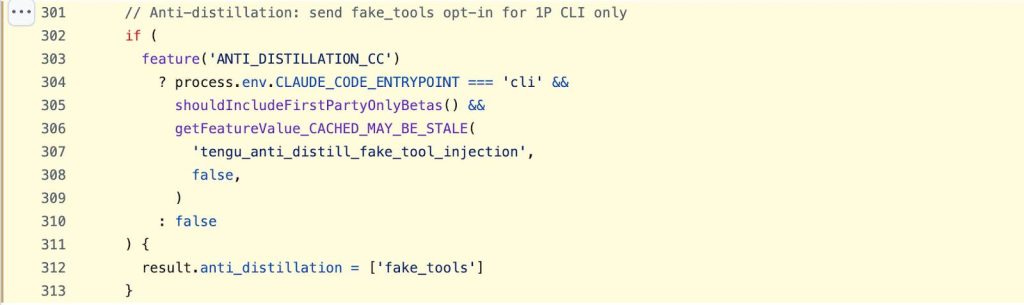
If a competitor captures API traffic to fine-tune their own model, those fake tools poison the training data. The distilled model learns to call tools that don’t exist in any real deployment, making it unreliable in production in ways that are difficult to diagnose.
streamlinedTransform.ts thinking content from output and summarises tool calls into category counts: searches, reads, writes, commands. Reconstructing Claude’s reasoning chain from captured traffic becomes practically impossible.


Separately, the binary uses native client attestation. Bun’s HTTP stack, written in Zig, overwrites a placeholder in the API request header with a computed hash at the transport layer, invisible to the JavaScript layer. The server validates this hash to confirm the request originated from an official Anthropic binary — effectively DRM at the network level, designed to prevent third-party wrappers from accessing Opus-tier models at lower pricing tiers.
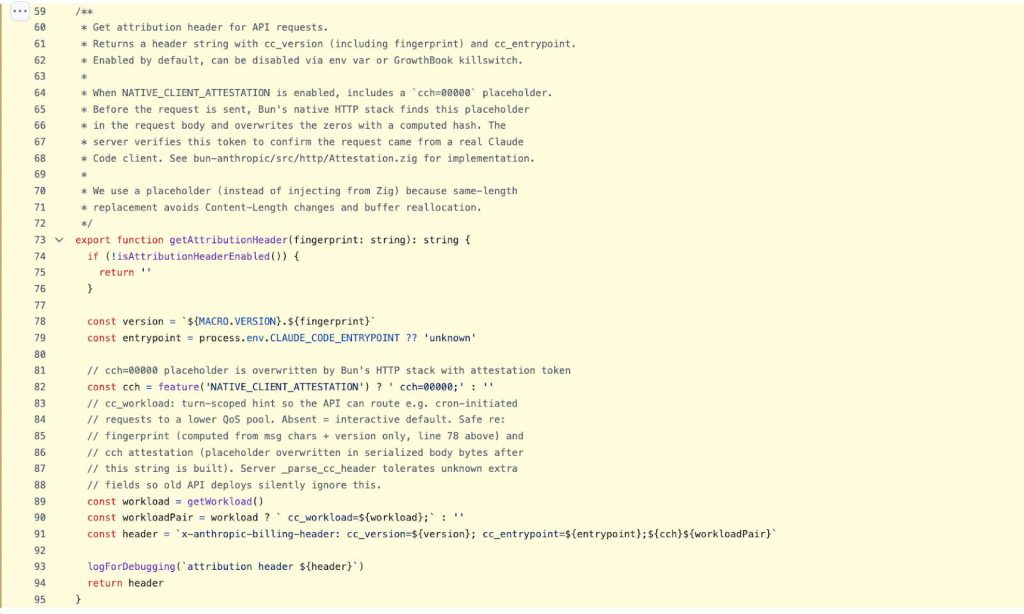
If you’re running an AI product and worried about traffic capture, fake tool injection costs almost nothing to implement and degrades any model trained on your data.
Default safe, not default convenient
When active, the system prompt gets an injection titled “UNDERCOVER MODE: CRITICAL” instructing Claude not to mention internal model codenames, unreleased version numbers, internal repo names, Slack channels, the phrase “Claude Code,” any indication of being an AI, or Co-Authored-By lines in commits.

‘If we’re not confident we’re in an internal repo, we stay undercover.’ That’s the right mental model for any sensitive operational mode.
The companion no one knew about
Even the spinner verbs are configurable
constants/spinnerVerbs.ts exports 187 verbs shown while Claude is thinking: Beboppin’, Bloviating, Boondoggling, Canoodling, Clauding, Combobulating, Discombobulating, Flibbertigibbeting, Lollygagging, Photosynthesizing, Razzmatazzing, Shenaniganing, and 175 more. The getSpinnerVerbs() function checks your settings for a spinnerVerbs config. mode: ‘replace’ swaps out the defaults entirely; otherwise your additions are appended.
This is a small thing that signals a team paying attention to texture. Loading states are dead time. Most tools show “Loading…” and leave it there. The replace-or-append config means enterprise users can strip the personality entirely while individual users can add their own. Details like this are what separate tools people tolerate from tools people enjoy using.
What this actually tells us.
512,000 lines of code written largely by agents, maintained by a team that delegates most of the implementation work to AI. The result is, by most accounts, a clean and well-structured codebase. One exception: a 3,167-line function in print.ts with 12 levels of nesting that shows exactly what agent-generated code looks like without structural review.
The patterns above didn’t come from architecture meetings. They came from production incidents, measured false-claims rates, 250,000 wasted API calls per day, and attack vectors that someone actually tried.
The question isn’t what Anthropic built. It’s which of these scars you’re going to inherit from a leaked source file rather than earn in your own production incident.








