




4.9 ![]()


Sheamus McGovern ![]()
Founder & CEO at ODSC


Ollie Maitland ![]()
Co-Founder & CPO at Capitalise

Jeff Wallace ![]()
Co-Founder at Silicon Valley in Your Pocket

Aaron Brooks ![]()
Managing Director and Co-Founder at WayThru Innovations

Rhodes Kriske ![]()
Marketing Director at WayThru Innovations

Michael Brady ![]()
COO at CR2

Ian Atkins ![]()
Co-Founder & COO at Choosing Therapy

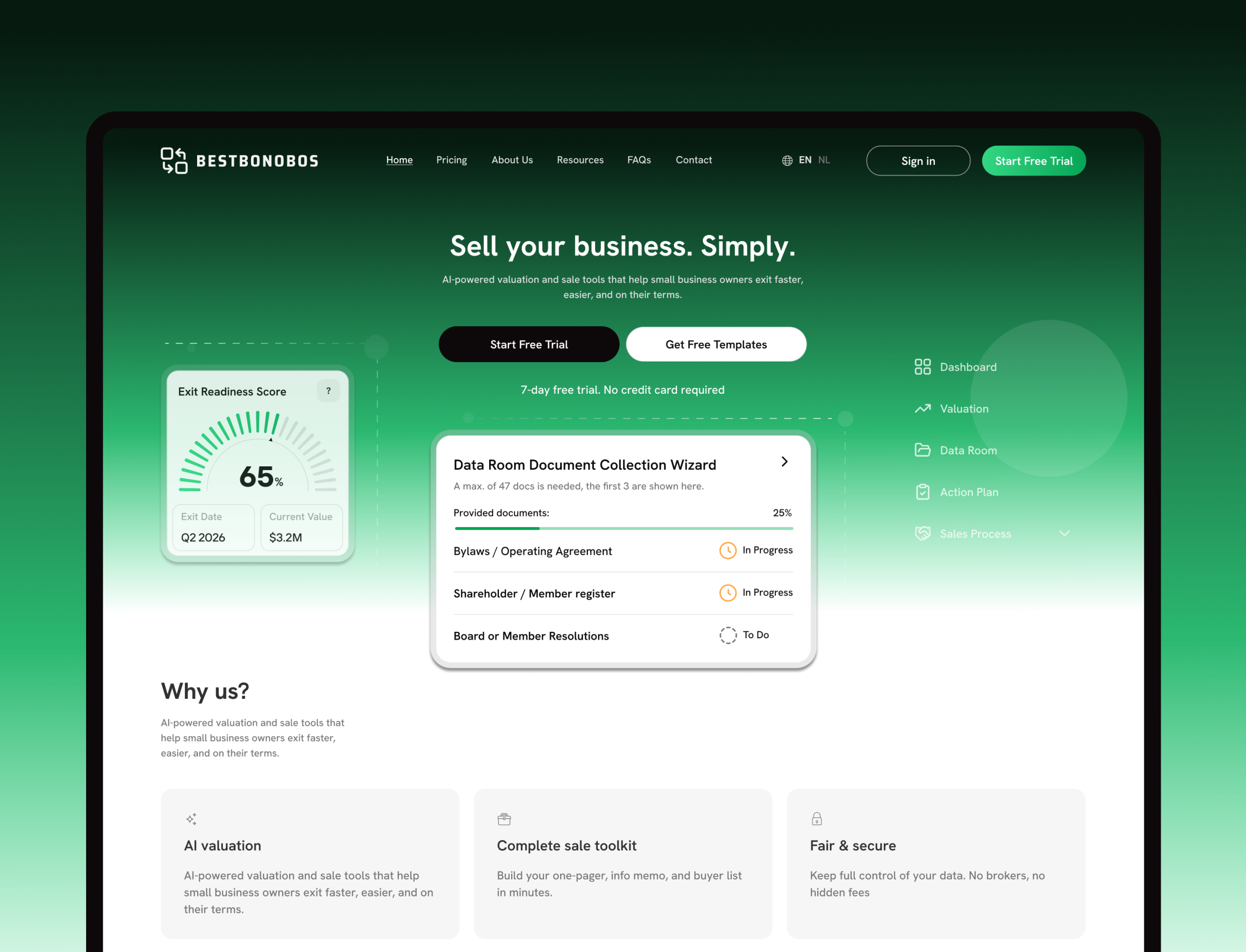
Sebastiaan Winter ![]()
Co-Founder at BestBonobos

Jonas Bertelsen ![]()
Chief Product Officer (CPO) at Cludo

Sam O’Brien ![]()
Co-Founder & Product Lead at Fillit

Steven Flynn ![]()
CEO, Founder at Skytango

Muhamad Gamal El Dean ![]()
Senior Project Manager at APC Ltd.

Alina Tivadar ![]()
Associate Project Manager at APC Ltd.

Matthew Rossi ![]()
CEO at Katara AI

Gil Plotnizky ![]()
Co-Founder and Director at Equilibrio


Michael Stone ![]()
Head of Engineering and Product at StrideUp

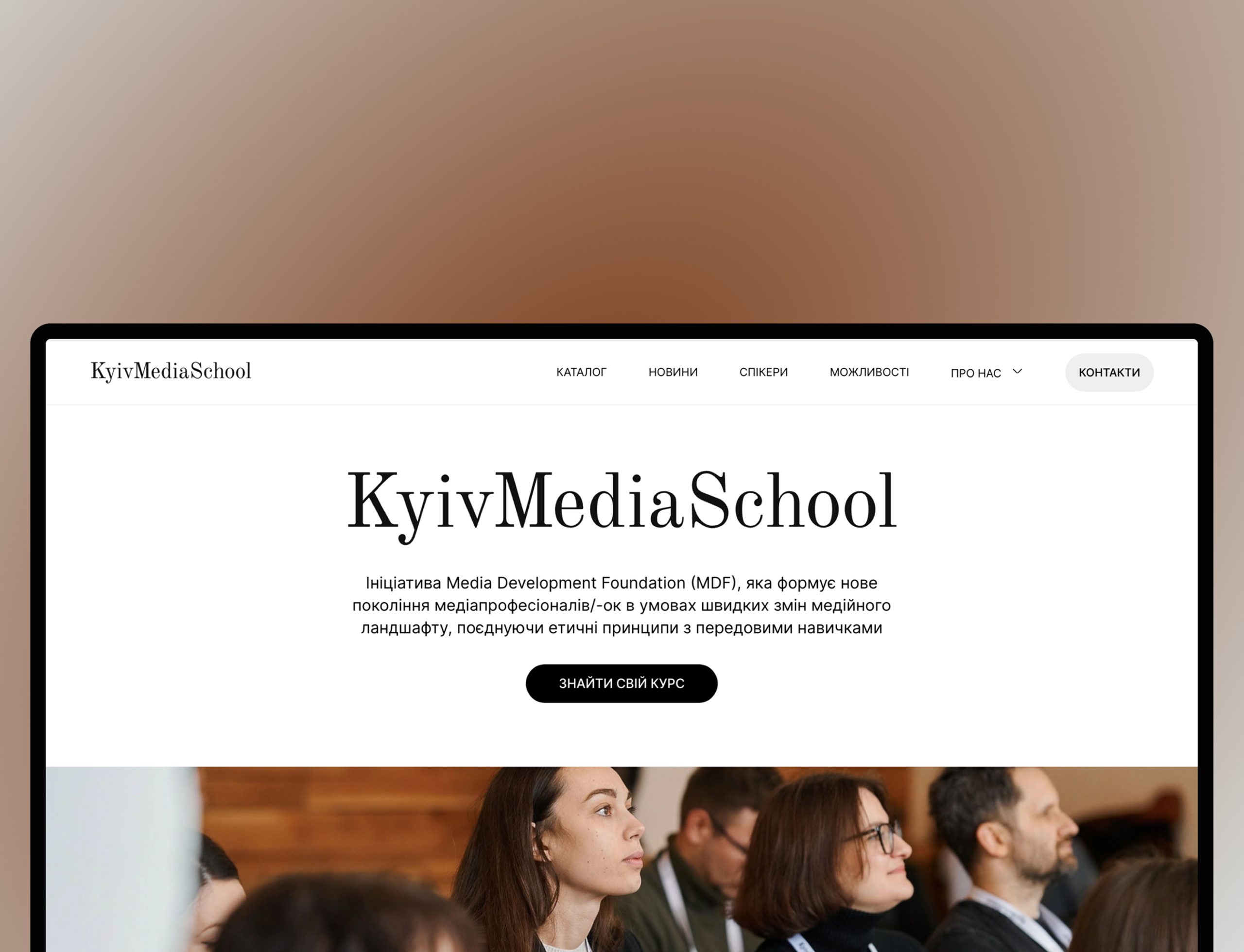
Artem Arutyunyan ![]()
Head of Digital at Media Development Foundation





