Introduction
Every marketplace platform has the same quiet problem. A user searches, finds something promising, and gets turned away. Venue at capacity. Wrong group size. Unavailable date. The booking fails, and the platform has two possible outcomes: the user tries again, or the user leaves.
Most platforms accept this as normal friction. A client of Ralabs decided to engineer around it.
The cost of a blank search page
The client runs a venue booking platform where users search for spaces to host events, from private gatherings to large corporate functions. When a venue could not accommodate a request, the platform previously had no structured way to respond. Users were simply rejected and left to restart their search manually.
A user who has specified location, group size, date, and requirements has demonstrated clear intent. Losing that user to a blank search page is a conversion failure with a direct revenue impact.
What the client needed was a fallback: a system that could surface relevant alternatives
at the moment of rejection, not a generic list of nearby options. The challenge was making those recommendations precise enough to be useful, fast enough to feel seamless, and explainable enough to earn user trust.
Why standard similarity search was not enough
The obvious starting point for any recommendation problem is vector similarity search. You embed your data, store it in a vector database, and retrieve items whose embeddings sit closest to the query. It works reasonably well for broad retrieval. It falls short when the differences between results actually matter, and AI search relevance becomes the deciding factor between a conversion and an exit.
Consider two music rooms returned by a vector database similarity search. Both match the query semantically. But one seats 30 people, the other seats 300. One is two kilometers away, the other is forty. For a user looking to host a 25-person event in a specific district, these are not equivalent options. A pure embedding model treats them as nearly identical. A user does not.
This is the gap that re-ranking addresses. Rather than relying solely on vector proximity, the system introduces a second stage that scores retrieved results against structured criteria: capacity fit, distance, property category, parking availability, and any free-text requirements the user has specified.
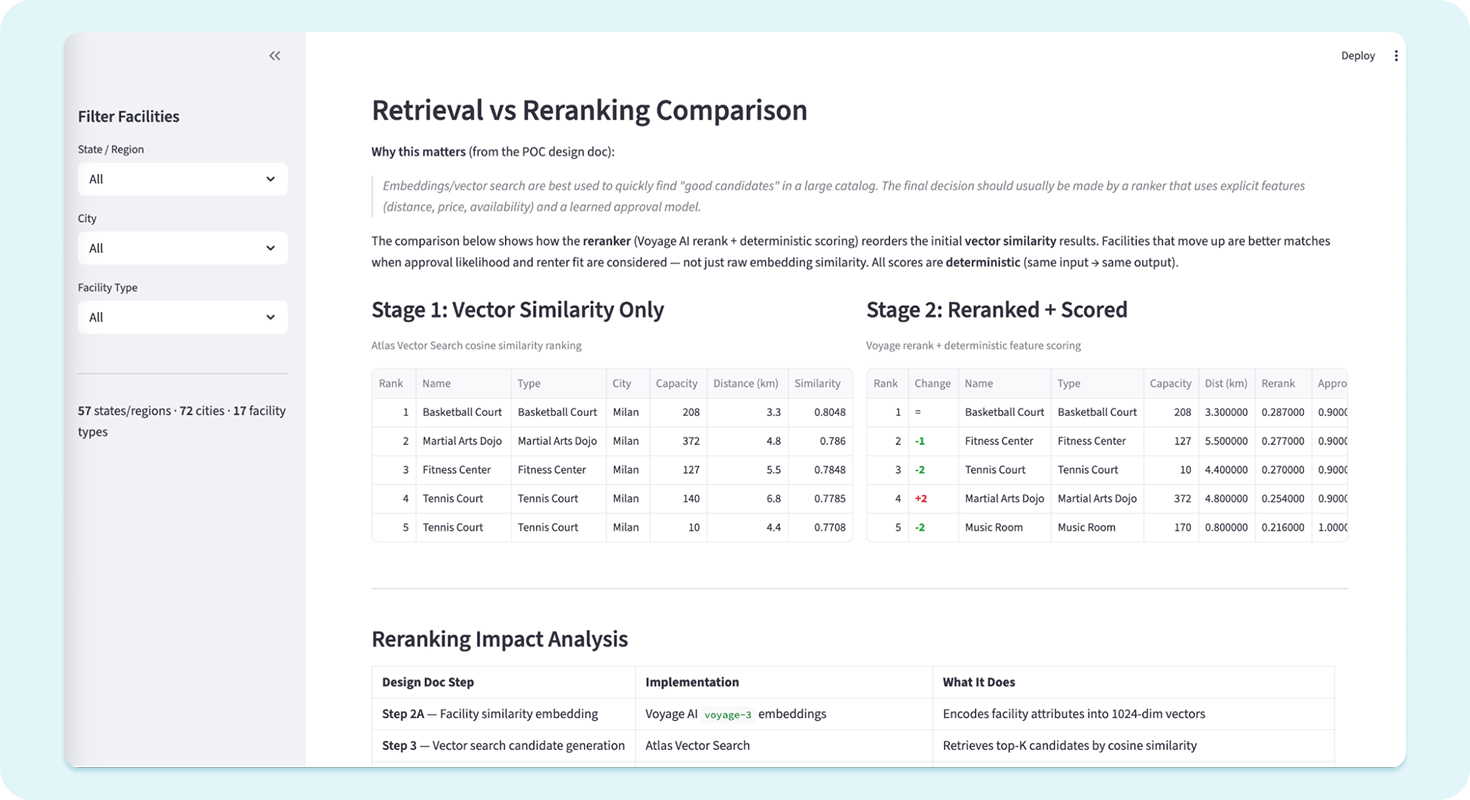
Ralabs implemented this architecture using Voyage AI, a third-party re-ranking model selected for its ability to interpret mixed signals. Numeric constraints like group size and distance radius are weighed alongside natural language inputs like “needs a stage” or “suitable for a music event.” The model handles free-text input without requiring the user to format their query in any particular way.
How the system works in practice
The full pipeline runs in three stages.
First, a vector search retrieves candidate properties from MongoDB using embeddings generated by Voyage AI. Vector embeddings are numeric representations of text that capture semantic meaning, allowing the search to pull anything matching the general profile of the refused booking within a configurable similarity threshold.
Second, the re-ranker evaluates each candidate against the user’s specific parameters. Capacity range, maximum travel distance, property type preferences, and any additional requirements provided in free text are all factored into a relevance score. Properties are reordered based on this score, not their raw embedding distance.
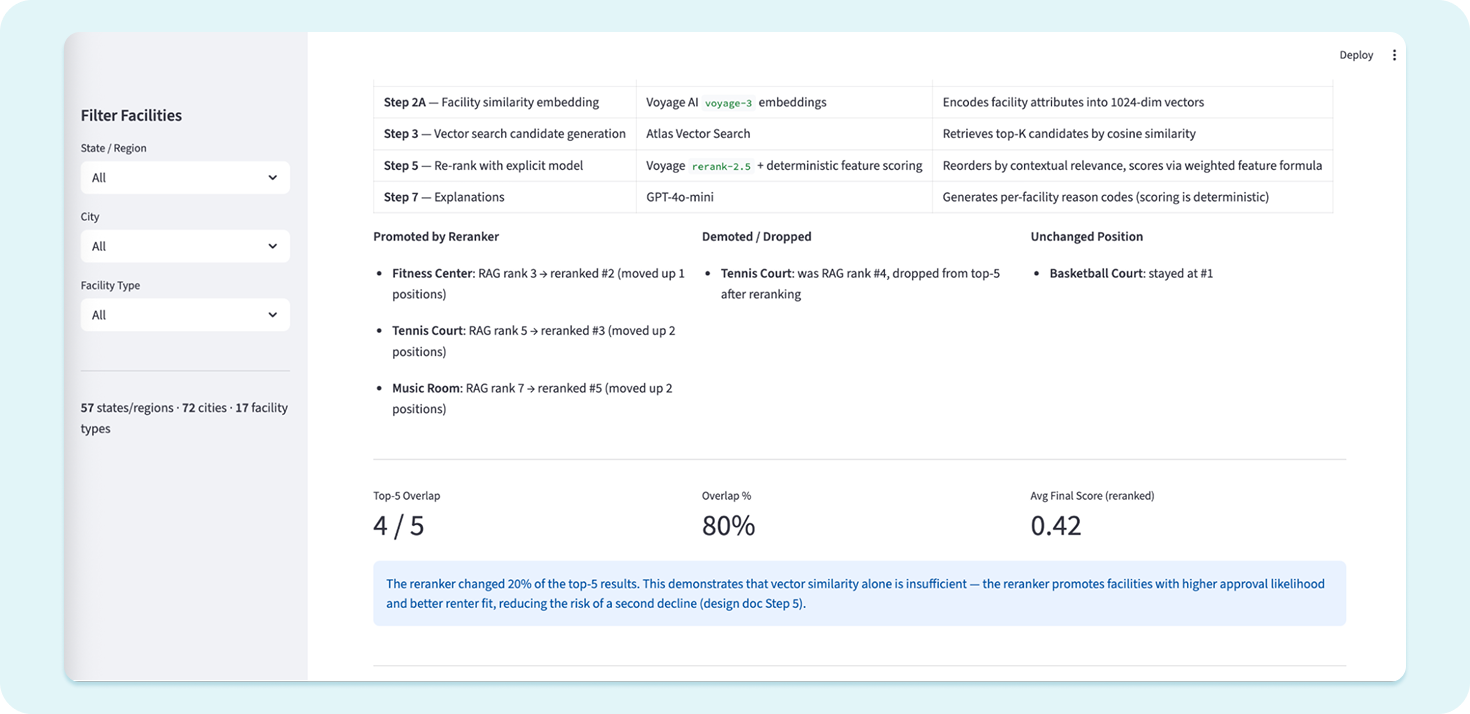
Third, a large language model (LLM) generates a plain-language explanation of each recommendation — delivering AI product recommendations tailored to the user’s original constraints, not a generic list.

The team built the entire pipeline within MongoDB, a deliberate choice that kept the implementation self-contained and portable, with no dependency on an external AI platform that cannot be swapped or extended later.
The Ralabs developer who built it estimates the total time, including two alignment calls and UI preparation for the demo, at under nine hours. Two years ago, comparable work would have taken two weeks.
What exactly re-ranking changes at the business level
A user who receives a relevant alternative at the moment of rejection is a user still in the funnel. The platform does not need to win back attention that was never lost. The recommendation arrives with context, with an explanation, and with enough specificity to feel considered rather than automated.
If a platform consistently suggests a 500-seat auditorium to a group of ten, users learn to ignore its recommendations. Re-ranking prevents that pattern from forming. The recommendations are grounded in the user’s actual constraints, scored against a formula the client controls, and explained in language the user can evaluate.
The system also gives the platform a feedback mechanism it previously lacked. Acceptance and rejection patterns across recommendations create a dataset that can be used to refine scoring weights over time. Which property categories convert best as alternatives? At what distance does a user stop considering a substitute? This data did not exist before because there was no structured fallback to generate it.
Limitations worth being clear about
The current implementation is a proof of concept. Business metrics, conversion lift and retention improvement, remain projections until the system runs against real user behavior.
One technical gap noted during development is the absence of availability date logic. Currently, the system recommends properties based on fit but does not account for whether a recommended venue is actually bookable on the requested date. In a live deployment, a highly relevant recommendation that turns out to be unavailable creates a different kind of friction. This is a known next step.
Hallucination risk in the LLM-generated explanations is mitigated by design. The model is not asked to reason freely about properties. It receives structured output from the re-ranker and generates a summary of that output. The explanations are grounded in data, not inferred from general knowledge.
What this approach generalizes to
Venue booking is the specific context. The architecture applies to any platform where users are rejected from a primary result and the cost of that rejection is measurable.
The same architecture applies to AI powered enterprise search scenarios: internal tools, supplier portals, or procurement systems where a failed query has measurable business cost. The pattern is consistent. Retrieve broadly, re-rank specifically, explain clearly.
The models exist. The infrastructure is standard. What remains is the decision to treat every rejection as a recoverable moment. Given that a working proof of concept now takes nine hours to build, that decision is harder to defer than it used to be.
Ralabs builds AI-powered systems for product teams that need more than a proof of concept. If you are dealing with recommendation quality, search relevance, or conversion drop-off at critical user moments, contact Ralabs to discuss your use case.