Why AI skill-building in engineering teams isn’t optional anymore
The myth that AI is coming for engineers’ jobs has been replaced by a much more urgent reality: AI is becoming part of the job.
In 2024, 76% of developers reported that they’re already using or planning to use AI tools in their daily workflow, according to Stack Overflow. And not just for fun – 72% said they view them favorably. Whether it’s speeding up coding, exploring APIs, debugging legacy systems, or generating boilerplate, AI has quietly slipped into the IDEs and terminal windows of the modern engineering team.
But tools are just the surface. The real shift is deeper – engineers today need to understand not just how to use AI, but how it works.
The webinar “Building AI Skills in Your Engineering Team” brought this shift into sharp focus. The session delivered a breakdown of what AI fluency actually looks like for engineers, how hiring expectations are evolving, and which skills will matter most in 2025.
What engineering teams are actually using
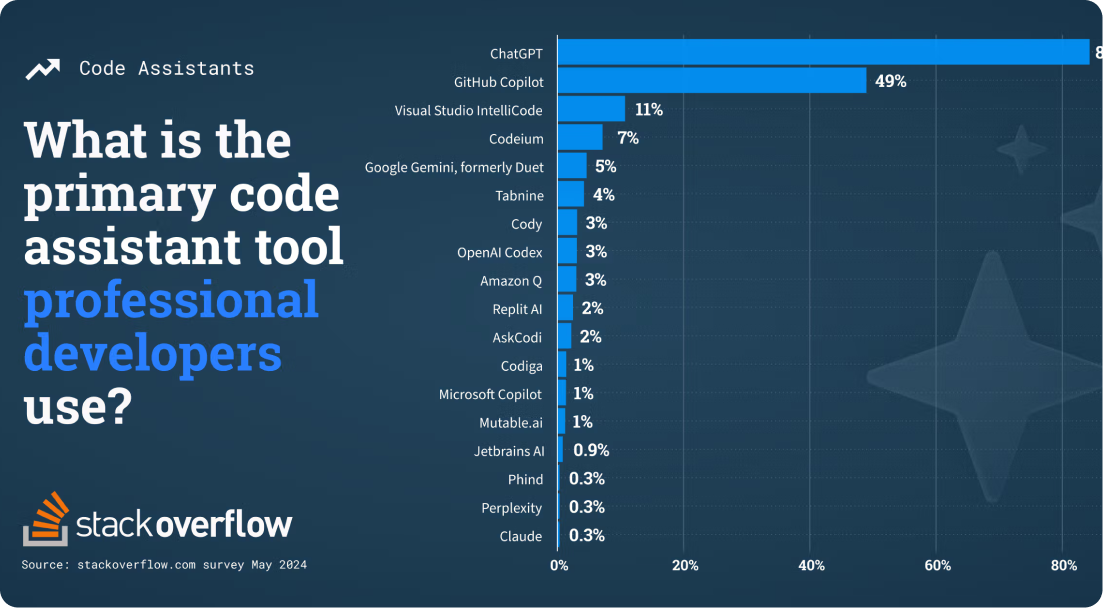
The AI tools that actually get used in engineering teams are the ones that quietly save time, reduce friction, and fit into existing workflows. During the webinar, we looked at the tools engineers are using not in labs, but in code reviews, CI pipelines, and long nights of debugging.
The usual suspects are all here: ChatGPT, Codium, Cursor, Hugging Face, and GitHub Copilot. But new contenders like PyCharm AI Assistant, Claude, and Bito are carving out niches too. One standout from the webinar’s visual data: a side-by-side comparison of usage stats showed that ChatGPT dominates for general-purpose prompting, but Cursor is gaining serious traction among developers for in-editor AI pair programming.
Still, adoption isn’t always smooth. Real-world engineers face real-world issues:
- Hallucinations: AI models still occasionally invent APIs, return incorrect formats, or fail silently.
- Outdated data: Many LLMs still lack real-time knowledge or hallucinate deprecated function names.
- Lack of explainability: AI may offer a solution, but often doesn’t explain why it’s correct – or if it even is.
To make these tools usable, engineers need to act like engineers. During the session, Ali Hesham, Data Engineer at Ralabs, showed how even a simple autocomplete prompt can go off the rails if you don’t constrain the output. One of his tips:
“When calling AI tools for API help, always ask for the most recent version. And don’t trust – test.
Ali Hesham, Data Engineer at Ralabs
The discussion also touched on an important psychological shift: AI is no longer treated as magic. It’s treated like a junior engineer. Helpful, often brilliant – but occasionally reckless.
We’ve helped companies roll out production-ready AI assistants, internal copilots, and automated research agents.

Head of Customer Success
Survey says: how 2024 shaped AI usage, and what’s next in 2025
If 2023 was the year of AI hype, 2024 has been its reality check – and its acceleration point. According to the ODSC Trends in AI survey, presented during the webinar, 84% of respondents now use AI tools to explore new ideas, speed up coding, or augment learning. Even more telling: 92% believe that developing AI fluency will help their careers.
This isn’t just about individuals tinkering with tools. Companies have started betting serious money on it. In 2024, AI startups broke records for investment, and practical applications – not prototypes – started hitting production across industries. Enterprise software, compliance automation, fraud detection, even internal documentation flows were all touched by LLMs.
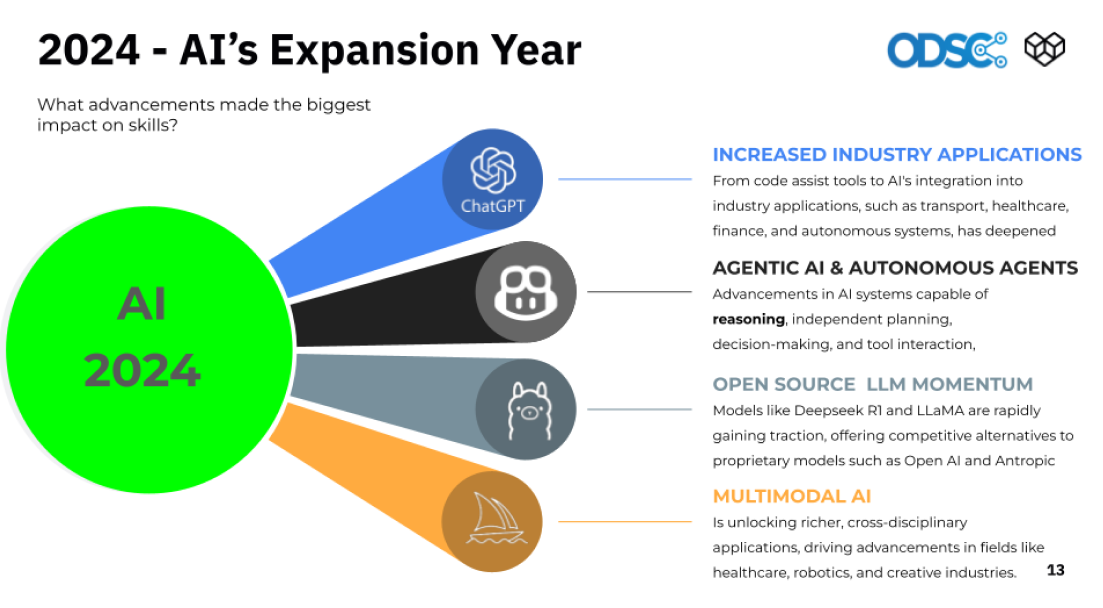
But the trend lines point forward. Our speakers highlighted four key trajectories that will define 2025:
- Reasoning over regurgitation: Future LLMs will be better at chaining logic and tracking objectives, not just answering prompts.
- Multimodal dominance: Models that understand images, charts, documents, and text together will unlock broader automation use cases.
- Agent frameworks: Reusable AI agents that carry memory, make decisions, and interact with tools are gaining traction fast.
- Specialization wins: Generic chatbots are out. Task-specific copilots – trained on domain data – are in.
During the Q&A, several attendees asked how to balance upskilling with project delivery. The advice? You don’t need to master every trend – but your team needs to understand where the ecosystem is headed and pick the tools and techniques that best serve your real use cases.
In short: don’t chase every wave. Learn to surf the ones that move your work forward.
Foundational AI skills every engineer needs (still)
In a world rushing toward no-code and auto-code, the engineers who stand out aren’t the ones avoiding complexity – they’re the ones who understand it well enough to bend it to their will.
The webinar made one thing clear: coding is not dead. In fact, it’s more important than ever. AI tools can autocomplete a function, but they can’t decide whether the logic fits your system, data model, or regulatory environment. That’s still your job
So what are the foundational AI skills every engineer should build?
Here’s the shortlist, straight from the webinar:
- Python – It’s still the backbone of AI development. From NumPy and Pandas to PyTorch and LangChain, Python remains essential.
- Statistics and probability – Just 20–30 hours of focused study can dramatically boost your ability to tune models, evaluate outputs, and avoid misleading metrics.
- Machine learning and LLM theory – You don’t need to build models from scratch, but understanding how they work – layers, embeddings, vector space – matters.
- Data wrangling – A well-structured dataset beats a clever model. Engineers should know how to extract, clean, and format data for model consumption.
- Prompt engineering – Structuring inputs, chaining steps, and maintaining version control on prompts are now core parts of the workflow.
- Problem-solving – Still the #1 skill engineers are hired for. AI can assist, but not replace, creative debugging and architectural thinking.
Ali and Sheamus emphasized that many engineers get overwhelmed trying to “learn AI” in one go. The better strategy? Build skills in layers, anchored to actual projects.
“Start by solving one small problem with AI – maybe automate a spreadsheet cleanup or classify support tickets. Then build from there. Real skill comes from repetition, not theory.
Ali Hesham, Data Engineer at Ralabs
This grounded approach echoed throughout the webinar: AI fluency isn’t a binary state – it’s a skill stack.
Languages, platforms, and tools that dominate the market
While the AI landscape evolves fast, the job market reveals a different story – one that’s slower, more stable, and easier to act on. The webinar dove into a detailed breakdown of 15,000 job descriptions from 2024 to spotlight which languages, tools, and platforms are actually in demand.
Let’s start with the basics. The top three programming languages mentioned across AI-related job descriptions:
![]() Far ahead of the rest. Appears in over 80% of AI-related listings.
Far ahead of the rest. Appears in over 80% of AI-related listings.
![]() Essential for data wrangling and analytics pipelines.
Essential for data wrangling and analytics pipelines.
![]() Still strong in traditional data science and academic sectors.
Still strong in traditional data science and academic sectors.
The verdict: if you’re building AI skills, Python should be your primary language. It’s not just widely used – it’s embedded in nearly every major AI toolchain: TensorFlow, PyTorch, Hugging Face, LangChain, FastAPI, Pandas, and more.
In terms of platforms and tools, here’s what hiring managers look for most (and where engineers should be focusing their attention):
| Tool / Platform | Usage area |
|---|---|
| TensorFlow / PyTorch | ML frameworks – modeling, training |
| Hugging Face | LLMs, transformers, open model hosting |
| LangChain | Building multi-step LLM workflows |
| Pandas / NumPy | Data processing, numerical ops |
| OpenAI API / ChatGPT | Prompting, prototyping, copilots |
| SQL / dbt / Airflow | Data pipelines, analytics workflows |
What’s particularly interesting is that classical machine learning still holds ground – especially in highly regulated industries like finance, healthcare, and insurance.
The takeaway: flashy tools come and go, but core infrastructure – Python, clean data, deployable models – remains the foundation.
Hidden signals from job descriptions
Here’s the uncomfortable truth: job descriptions often lie – or at least, they’re two steps behind reality. During the webinar, the team unpacked their analysis of 15,000+ AI-related job postings across 2024 and found that many descriptions are recycled, vague, or missing the most critical skills altogether. Companies might list “Python” or “machine learning,” but what they actually want is someone who can build and ship LLM-powered features, manage data pipelines, or debug multi-agent workflows.
So what should engineers really look for in job listings?
Hidden but essential skills (frequently buried or missing):
- Natural Language Processing (NLP) – especially with domain-specific data
- MLOps – versioning, deployment, monitoring of models in production
- Vector database integration – crucial for retrieval-augmented generation (RAG)
- Prompt engineering and tuning – not always named, but heavily implied
- Understanding of transformer-based architectures – or at least their implications
“Most companies haven’t figured out how to write AI job descriptions yet – but they still want engineers who can deliver AI-driven features. So don’t just read the bullets. Read between the lines.
Ali Hesham, Data Engineer at Ralabs
Another tip from the webinar: when you see the phrase “experience with AI tools”, it’s often a placeholder for “we want someone who can figure out what tool to use, and how to use it well.” That includes scripting, adapting models to datasets, prompt tuning, and building agents that don’t go off the rails.
To stay ahead of the curve, engineers should map real project needs to the job market language, and train accordingly. The AI job of the future won’t come with a tidy title – but the work will still need doing.
The LLM Engineer: job title or just better engineering?
A new role has started popping up on job boards and in engineering circles: the LLM Engineer. At first glance, it sounds like yet another tech buzzword. But dig into the actual responsibilities, and you’ll find it’s less about titles – and more about expectations.
In the webinar, the team unpacked several real job posts for LLM Engineers. What they found was revealing: most of these roles weren’t fundamentally different from senior backend or full-stack engineering positions. The twist? Employers now expect:
- Experience with OpenAI, Claude, LLaMA, or custom models
- Ability to manage vector stores (like Pinecone, Weaviate, or Chroma)
- Skills in prompt engineering, retrieval augmentation, and multi-agent flows
- Strong debugging abilities for model hallucinations, context length issues, and reasoning failures
- Comfort writing tests and performance checks for non-deterministic outputs
But here’s the kicker: many companies are still advertising for a “Software Engineer” – and quietly expecting them to do all of the above.
“They’ll ask for a regular engineer, and then expect ML, LLMs, vector search, and prompt engineering on top. The title hasn’t caught up to the work.
Sheamus McGovern, Founder, ODSC
So what makes someone a strong LLM Engineer, whether or not their title says so?
- They understand how LLMs think – token context, embeddings, completion strategies
- They approach prompts like structured programs, not one-off hacks
- They know how to build wrappers, retries, and tests around unpredictable model behavior
- They obsess over observability – tracing bad results back to prompt failures or data issues
The rise of agentic AI: what engineers need to know
If 2023 was the year of the chatbot, 2024 is quickly becoming the year of the agent.
Unlike single-shot prompts, agentic AI systems are designed to perform multi-step reasoning, interact with tools and APIs, and even loop through tasks until goals are met. They go beyond answering – they act.
The typical agentic architecture that’s becoming common in production settings is:
- Language Model – the core reasoning engine (GPT, Claude, Mixtral, etc.)
- Memory – persistent or short-term memory to track interactions and goals
- Retriever – interfaces with a vector database (e.g., Chroma, Weaviate) to fetch context
- Toolset – APIs or internal functions the agent can call (search, fetch, execute)
- Controller – manages task planning, looping, and execution flow
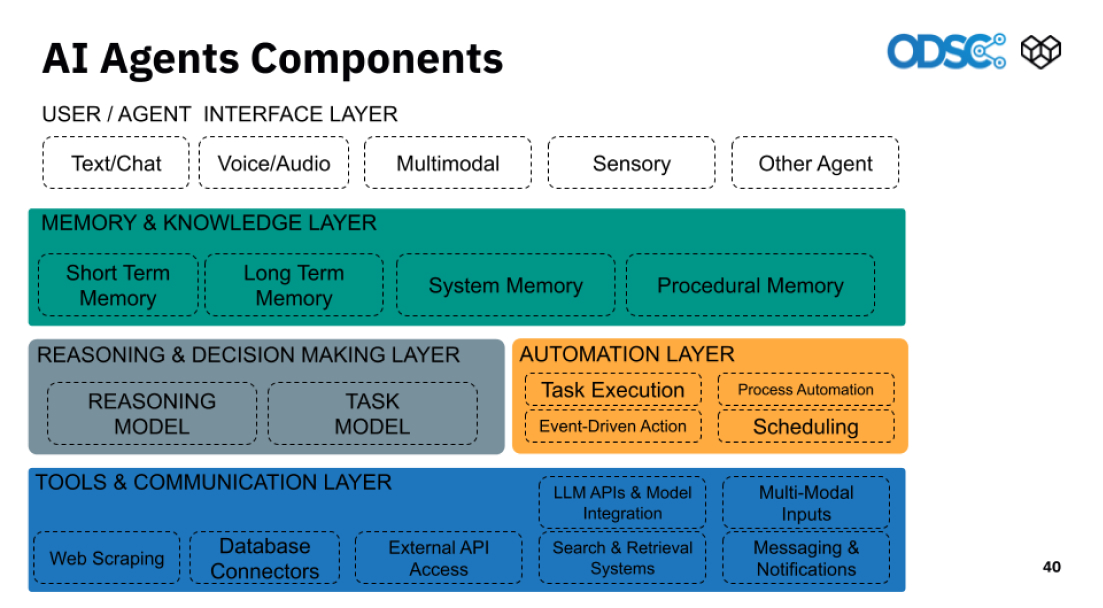
Popular frameworks like LangChain, CrewAI, LlamaIndex, and Autogen are making this accessible – but they’re also abstracting complexity.
Real-world use cases discussed:
- Research assistant – an agent that reads documentation, compares APIs, and summarizes options
- Customer support triage – routing tickets based on analysis of user input and account history
- Internal tools – automating updates to databases or triggering workflows across systems
Webinar poll results backed this up:
- 51% of attendees said they’re already using agents in some form
- Another 78% plan to implement them within the next 6–12 months
But with power comes responsibility. Agents can cause real damage – from overcalling APIs to misinterpreting instructions – if not tightly scoped and tested. Observability, retries, and clear limits are essential.
The advice to engineers: learn how to design agents like you’d architect a backend service. Because that’s exactly what they’re becoming.
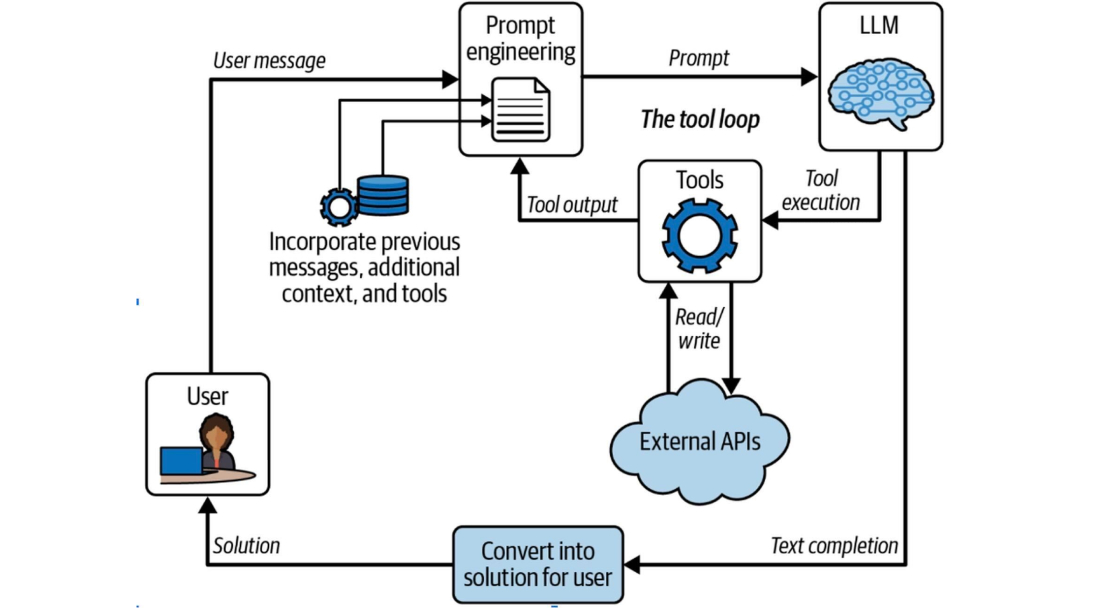
Prompt engineering vs prompt design: the real difference
Not all prompts are created equal. While “prompting” might sound like a soft skill or a creative task, the reality is more technical and structured than most engineers assume.
A key distinction between two emerging practices are:
- Prompt Design: Crafting prompts intuitively, often by trial-and-error. Useful for ideation, but hard to scale and impossible to debug.
- Prompt Engineering: Applying consistent structure, testing, version control, and context-aware formatting. It’s software development – just at the language layer.
To illustrate the difference, Ali walked through two examples:
- Poor prompt: “Give me a summary of this website about Paris.” → Result: ChatGPT generated a generic tourist summary with outdated or irrelevant details.
- Engineered prompt:
- Defined format (JSON)
- Limited tokens per section
- Clear instruction to avoid speculation
- Included input type (e.g. scraped HTML) and purpose →
- Result: A structured, accurate, reusable component that could power a research or content app.
He also demoed a prompt for Hugging Face API documentation, where the model was guided to extract features, format output, and keep responses below a token limit – all defined in a prompt template.
Key techniques discussed:
- Chain of Thought (CoT) – Let the model “think aloud” step-by-step
- Few-shot prompting – Provide 2–3 examples for pattern consistency
- Self-consistency – Run multiple completions and average the answers
- Versioning – Store prompts like code: track changes, test, roll back
- Prompt testing – Score prompts with metrics like helpfulness, completeness, hallucination rate
Ali emphasized that prompt engineering should be treated like software architecture. The more structured and testable it is, the better your results – and the easier it is to scale across teams.
Final thoughts
The future of engineering isn’t about becoming a data scientist. It’s about building systems that are smart by design – and that means understanding how to integrate, evaluate, and guide AI like any other part of the stack.
AI skills aren’t optional anymore – but they’re also not mystical. Like any engineering discipline, they can be learned through layered practice, sharp tooling, and good habits.
Here’s your AI skill-building playbook:
- Pick a real problem you or your team faces – automate, augment, or analyze
- Choose the right tools – Python, LangChain, OpenAI, Hugging Face, dbt, etc.
- Structure your prompts – use templates, tokens, and test cases
- Version everything – treat prompts and model configs like source code
- Don’t skip the stats – basic evaluation metrics go a long way
- Focus on observability – build in logging, scoring, and feedback loops
Finally: don’t go at it alone. Whether it’s through curated bootcamps, community projects, or webinars like this one, the fastest way to grow is to build in public, share your findings, and stay close to where the tech is moving.
Until next time – build like an engineer, prompt like a systems thinker.
And if your team is ready to turn AI fluency into real product velocity – whether through smarter tools, custom agents, or LLM integrations – we’d love to help you get there.