Introduction
Software teams today ship faster than ever. AI-assisted coding, vibe-coded MVPs, and rapid prototyping have become standard. Across many projects, we see the same thing happening: products reach production quickly, while technical debt and quality issues build up in parallel. As teams scale, quality stops being a checklist or a function of a few senior engineers. It becomes an operational concern that directly affects reliability, client trust, retention, and long-term revenue.


These trends were the starting point of my talk at the WAWTECH Tech Conference in Warsaw on December 16–17. A conference that brought together more than 5000 engineers. I shared our learning of building software quality framework to manage more 50 projects on same time,and how we see software quality changing in the AI era, why traditional approaches struggle, and how we at Ralabs design quality systems that work in real, multi-team environments. The focus was not on theory, but on practical structures that help teams observe quality early and act before problems become costly.

Common quality failures at real-world scale
Before discussing systems or tooling, it is worth looking at the types of quality issues that tend to surface once a product is running in production and serving real users. Many problems remain invisible during development and early testing, only becoming obvious when systems are exposed to real load, real data, and real usage patterns. One recurring pattern is architectural debt that becomes visible only under sustained or unexpected load.
Investments in architecture are always “expensive” and never feel timely, but a product should always be built with the belief that it will succeed. That is why the architecture must be ready for 10x scale – to handle more users, more traffic, and to withstand attacks, and so on.


Why most AI projects fail and how to fix that
Another recurring issue appears during releases. We have seen React applications pass automated tests, behave correctly on developers’ machines, and still fail immediately in production. In most cases, the cause was not a single bug, but missing validation steps – incomplete UAT, unrealistic pre-production data, or the absence of real user scenarios. These failures were not the result of poor engineering in isolation, but of gaps in how quality was observed, validated, and stress-tested across environments.
These failures had one thing in common. They were not caused by a lack of effort or competence, but by the fact that quality issues were discovered too late. That realization pushed us to formalize how we observed and assessed quality across teams.
How we moved from manual checks to AI
Our first approach to software quality was entirely manual. We built detailed engineering playbooks across architecture, security, infrastructure, frontend, backend, documentation, and team practices. Teams periodically answered structured surveys, which we aggregated into project health scores to track consistency in how practices were applied.
The core issue was timing. These assessments acted as lagging indicators. By the time a project turned red, the underlying problems had often existed for weeks or months. We later wrapped the process in an internal platform with dashboards and visual comparisons, which improved visibility but not outcomes. Teams still had to answer hundreds of questions and decide what mattered. Awareness increased, but early intervention and prevention did not.
At that point, it was clear that better tooling alone would not be enough. Any next step had to change not only speed, but how teams related to the system itself.
What had to be in place before AI could work
Before applying AI to software quality, we focused on something more fundamental: trust and creating a proper environment.
At Ralabs, we had already started building small operational AI agents across the company: HR onboarding assistants. Legal document validators. Delivery agents that converted meeting transcripts into Jira actions. Metrics agents that analyzed internal data.

The goal was not to build a single perfect system, but to create many small agents that solved narrow problems well. This approach helped people get used to collaborating with AI rather than treating it as an external evaluator.

That mattered for quality. Software quality is deeply human. If engineers feel monitored rather than supported, the system fails regardless of how advanced it is.
Once teams were comfortable working with AI as an assistant rather than an auditor, we could start applying it to software quality in a much more direct way.
From manual assessments to an agentic SQM platform
As the number of projects grew, even assisted workflows stopped scaling. Quality had to be measured continuously and consistently across all projects, without relying on periodic reviews or manual coordination. We moved from isolated AI agents to building an agentic Software Quality Management platform that observes repositories, documentation, delivery pipelines, and team signals across the entire portfolio.

Quality playbooks define what to measure for different contexts, while agentic workflows execute them automatically and keep signals up to date as projects evolve. This turned quality management from a manual process into an always-on system, giving teams and leadership a shared, real-time view of where attention is needed and why.
How AI suggests answers inside SQM

Instead of asking teams to recall information from memory, SQM is designed to work directly with the project’s existing knowledge. Documentation, internal guidelines, repositories, and other sources are continuously processed by the system. When any source is added or updated, SQM converts that content into embeddings and stores them in a vector database. This means the system always works with the latest version of project knowledge, not outdated snapshots.
When a quality question appears, for example whether a mandatory UAT step exists before release, SQM does not guess. It searches the vector database for relevant context and suggests an answer based on what is actually documented. This approach is based on a Retrieval-Augmented Generation architecture. If relevant information is found, the system proposes an answer with confidence indicators. If no reliable context exists, the question remains intentionally unanswered and is passed to a human.
This behavior is deliberate. Unanswered questions are not treated as failures. They highlight gaps in documentation or unclear processes. Over time, this helps teams see not only what they know, but also what is missing. In practice, AI shifts quality discussions away from subjective opinions and toward observable signals grounded in real project data.
Asking fewer questions and getting better answers
Another structural problem was volume. Some playbooks contained more than five hundred questions. Asking everyone everything created fatigue and noise.
We introduced an SQM survey agent that routed questions based on role and competence. Frontend engineers no longer answered backend infrastructure questions. Backend teams focused on backend topics. Quality questions became targeted rather than broadcast.

The agent also suggested answers for each question. Engineers could confirm or override them. After human input, AI performed semantic vetting to check for inconsistencies. This reduced subjective scoring and removed many human errors.
The result was simple: fewer questions and higher quality answers. Less resistance from teams.
From answers to concrete actions
Answering quality questions was useful, but it did not solve the core problem unless those answers led to decisions and execution.
Previously, experienced engineers manually reviewed survey results to identify risks and propose actions. This approach did not scale.

We built an SQM insights agent that analyzed answers and generated an impact effort matrix. It suggested which findings required immediate attention, proposed solutions, estimated effort in hours, and prepared Jira tickets with context and acceptance criteria.
Leadership discussions changed as a result. Instead of debating scores, teams discussed priorities, tradeoffs, and concrete next steps.
Quality management moved closer to product management, where decisions are driven by impact rather than compliance.
From answers to concrete actions
Even with clearer actions, some aspects of quality remained invisible because they could not be reliably assessed by human judgment alone.
Some quality signals cannot be answered by humans at all. One example I shared at WAWTECH was tracking the percentage of AI generated code on a production branch.
This required calculation rather than search.
We built a system where metrics could be defined in natural language. The platform fetched relevant data from sources like GitHub, generated a schema, produced calculation code, and executed it in a controlled environment.

The output was a numeric metric, not an opinion. This allowed us to observe where AI assisted development delivered better results and where it did not.
We deliberately avoided generic execution frameworks here. Control and determinism mattered more than flexibility.
Code quality in an AI assisted workflow
We also tested several automated code review agents. Over time, we settled on CodeRabbit.
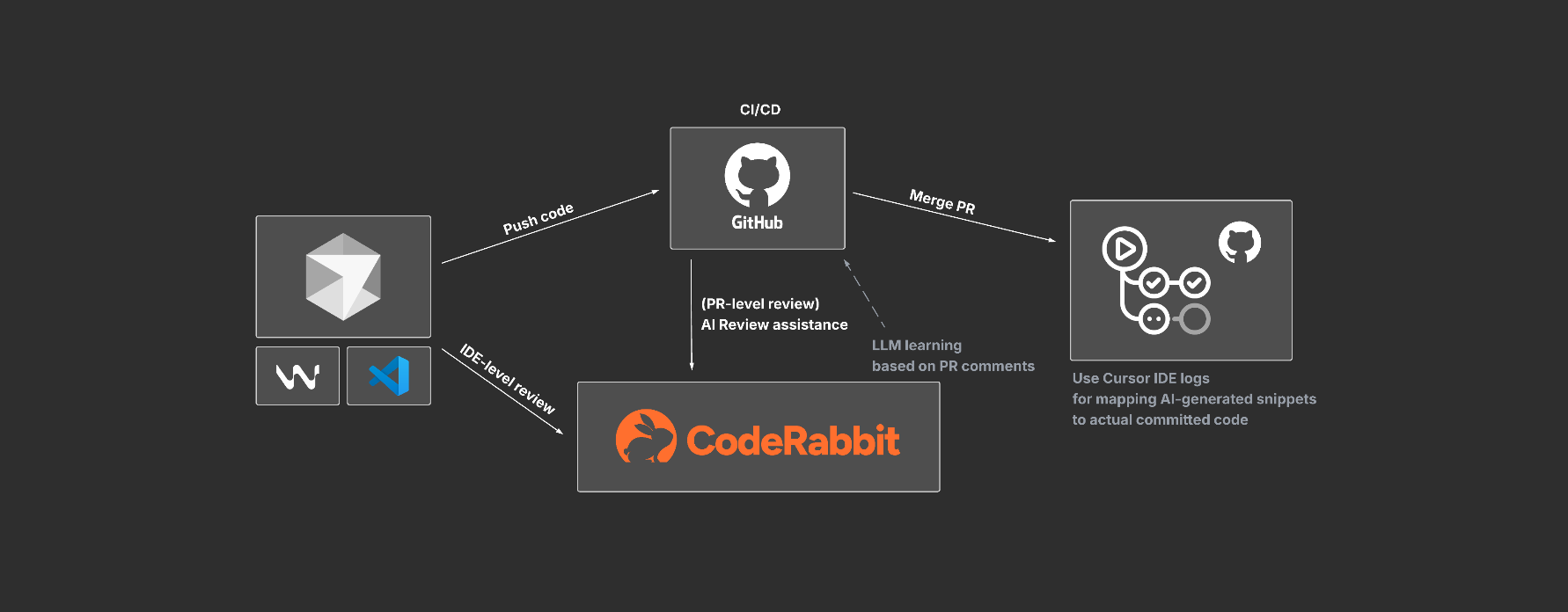
What mattered was learning. As the system adapted to our codebase and review patterns, feedback became more relevant. Combined with Cursor IDE logs, we could correlate AI generated snippets with committed code.
This allowed us to measure AI impact on the codebase rather than relying on anecdotal feedback. Teams reported higher confidence in decisions. Velocity gains were secondary.
Code quality was a natural extension of this approach, especially in workflows where AI was already actively contributing.
What we learned along the way
Several conclusions emerged while building and operating this system:
- Continuous measurement creates positive pressure even before metrics are perfect. Visibility alone changes behavior.
- Transparency increases engagement. Engineers respond better to observable quality signals than to abstract guidelines.
- Simplicity determines adoption. When non-technical stakeholders can interact with quality data, conversations improve.
- AI reduces optimism bias when it validates after human input rather than before.
- Smaller teams benefit more from AI, especially on new or isolated projects. Long term complex maintenance remains harder.
- Senior engineers paired with AI become multipliers, not because of experience alone, but because they adopt learning loops faster.
- The largest productivity gains appear when teams start using AI. Incremental improvements later are smaller.
What this changed for us
At Ralabs, AI did not replace engineering judgment. It changed where that judgment was applied, away from collecting data and toward deciding what to do next.
The most important lesson for us was simple. AI did not reduce the complexity of software quality. It removed ambiguity by forcing decisions to be based on observable signals rather than assumptions.
That was the core message of my talk at WAWTECH, and it remains the direction we continue to invest in.
Leave your email to access the full recording.

Here is the link to the recording.
Have a great day, and enjoy the insights!
If you are building complex products and want a clearer, more objective view of software quality across teams, we are open to discussing how this approach could apply to your context. At Ralabs, we work closely with founders and product leaders to design quality systems that scale without losing control.
You can also connect with me on LinkedIn to continue the discussion and follow practical engineering insights.