Customer location: The US ![]()






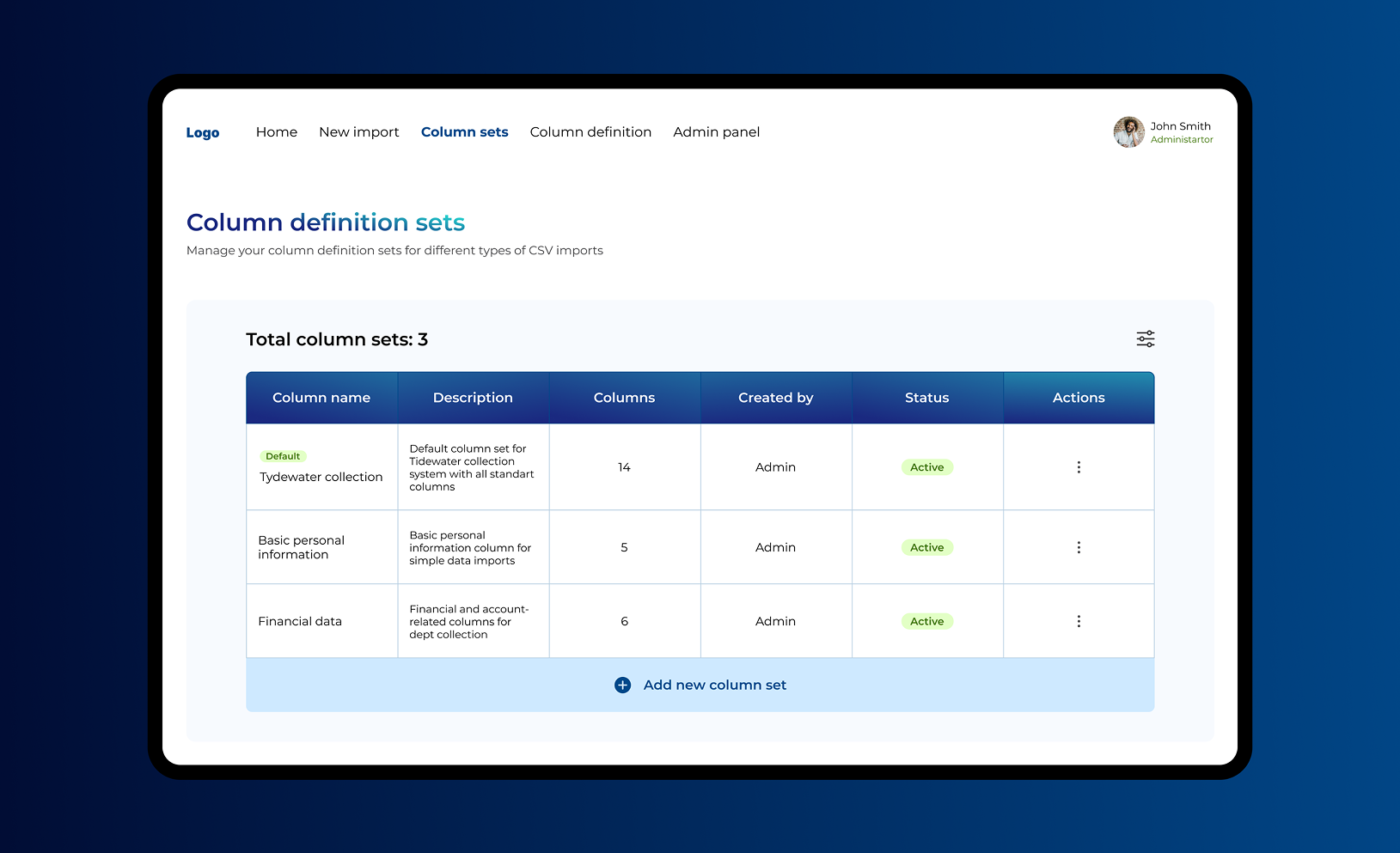







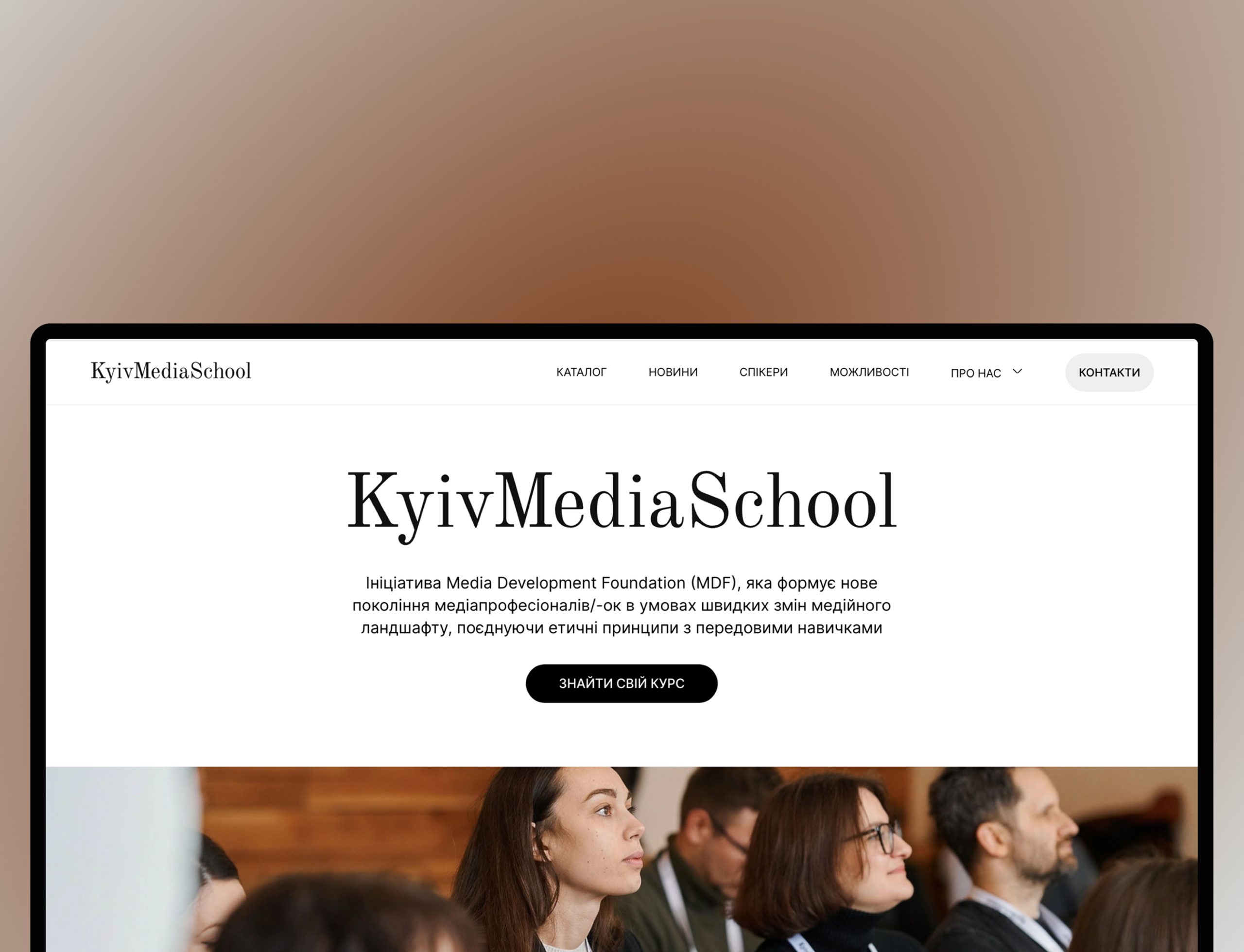
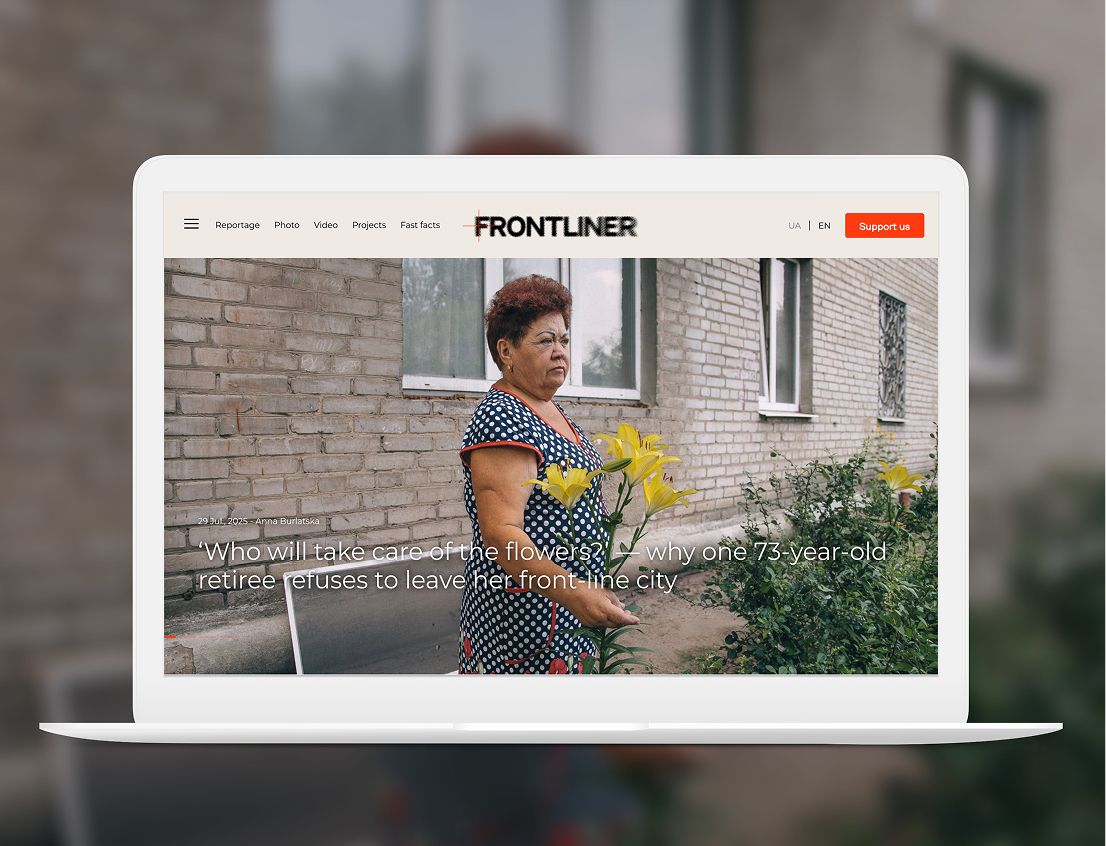

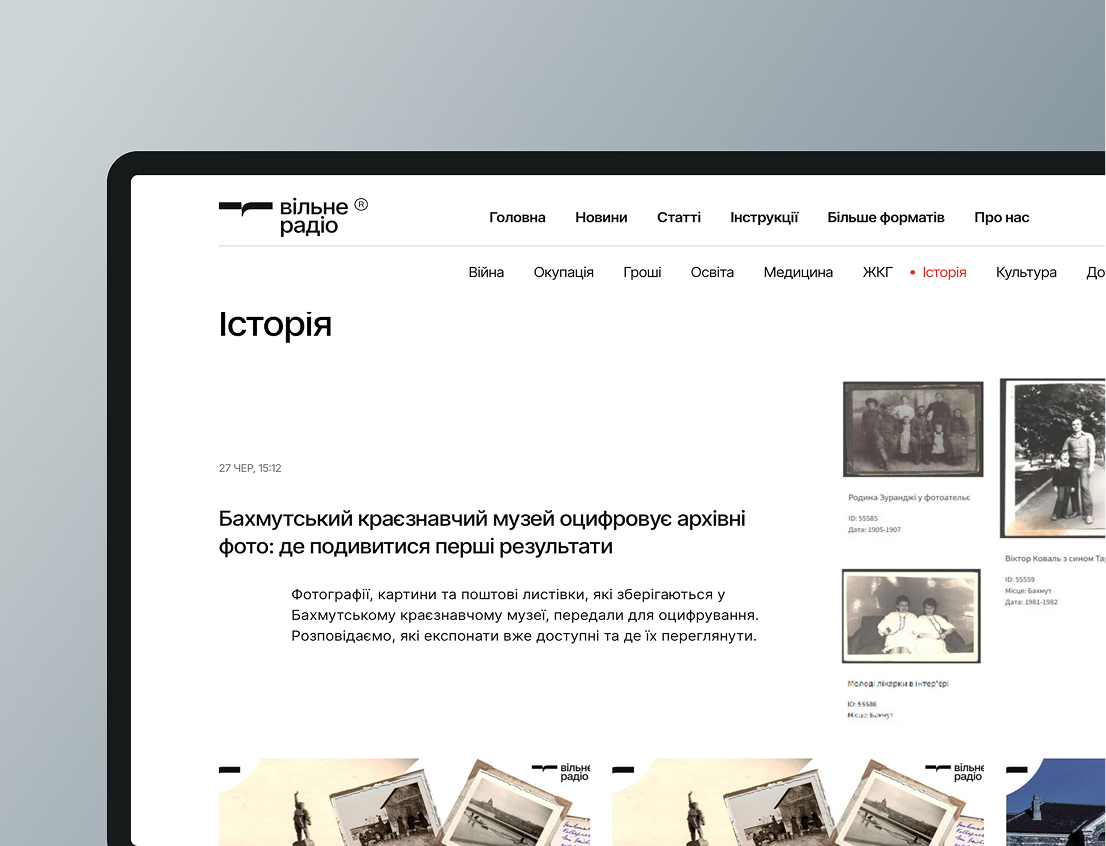

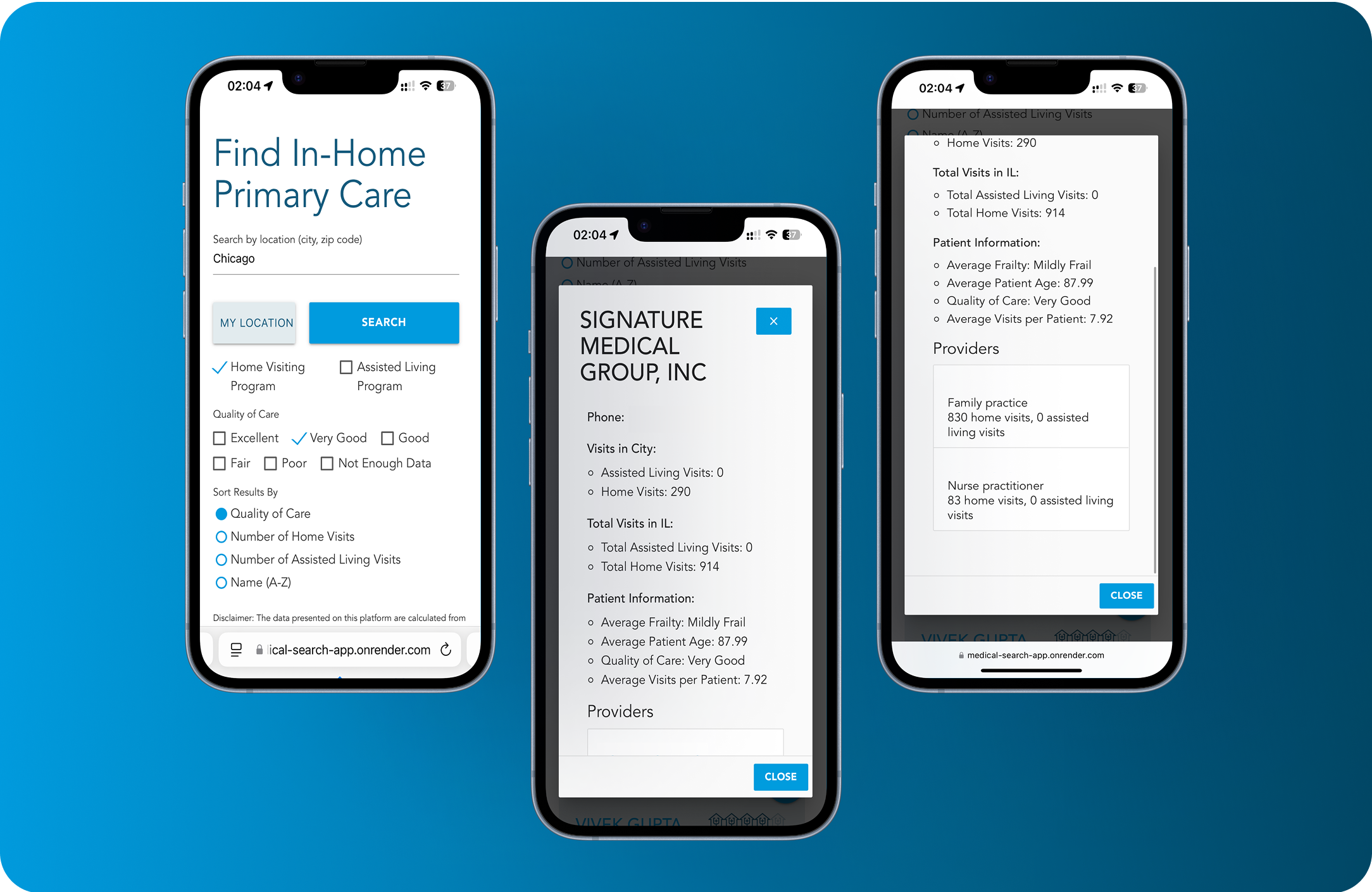
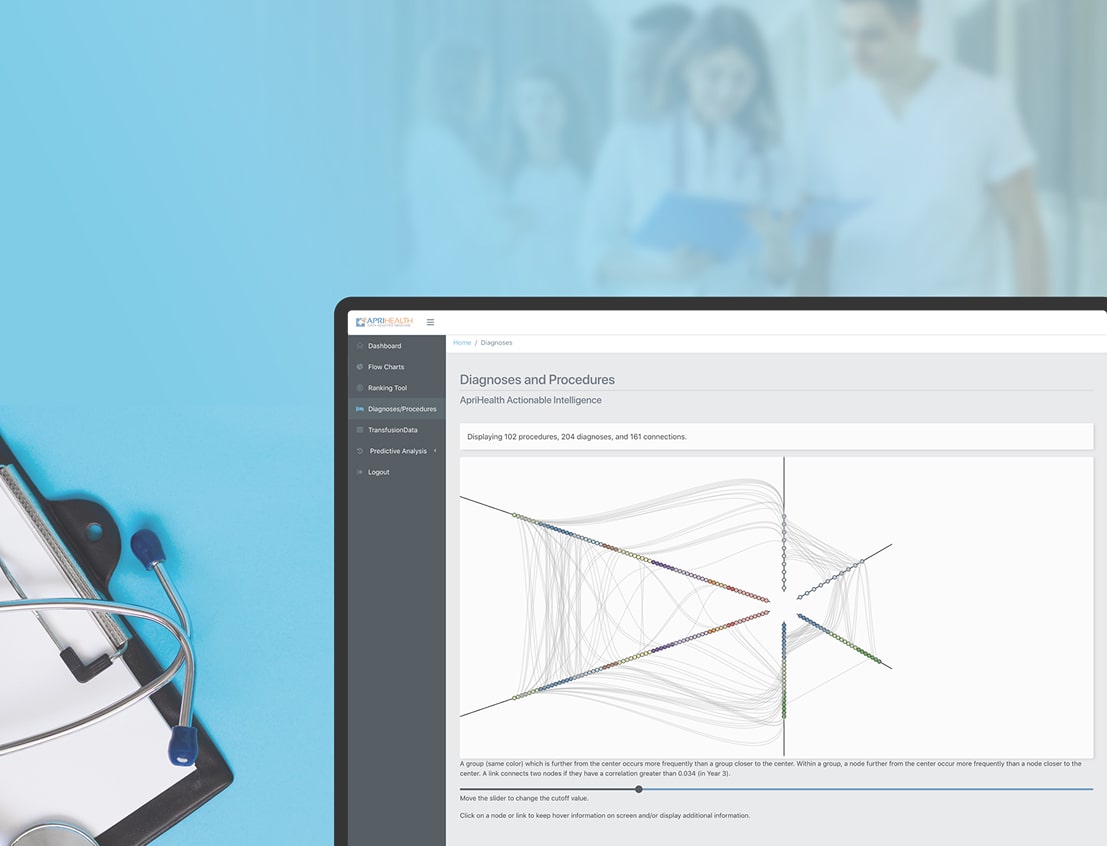
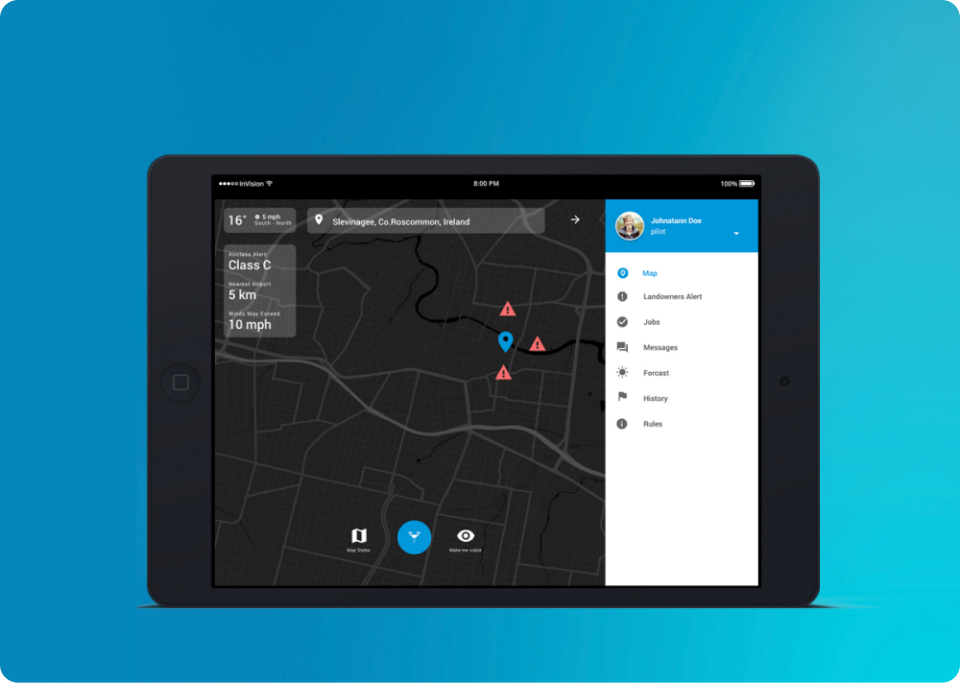

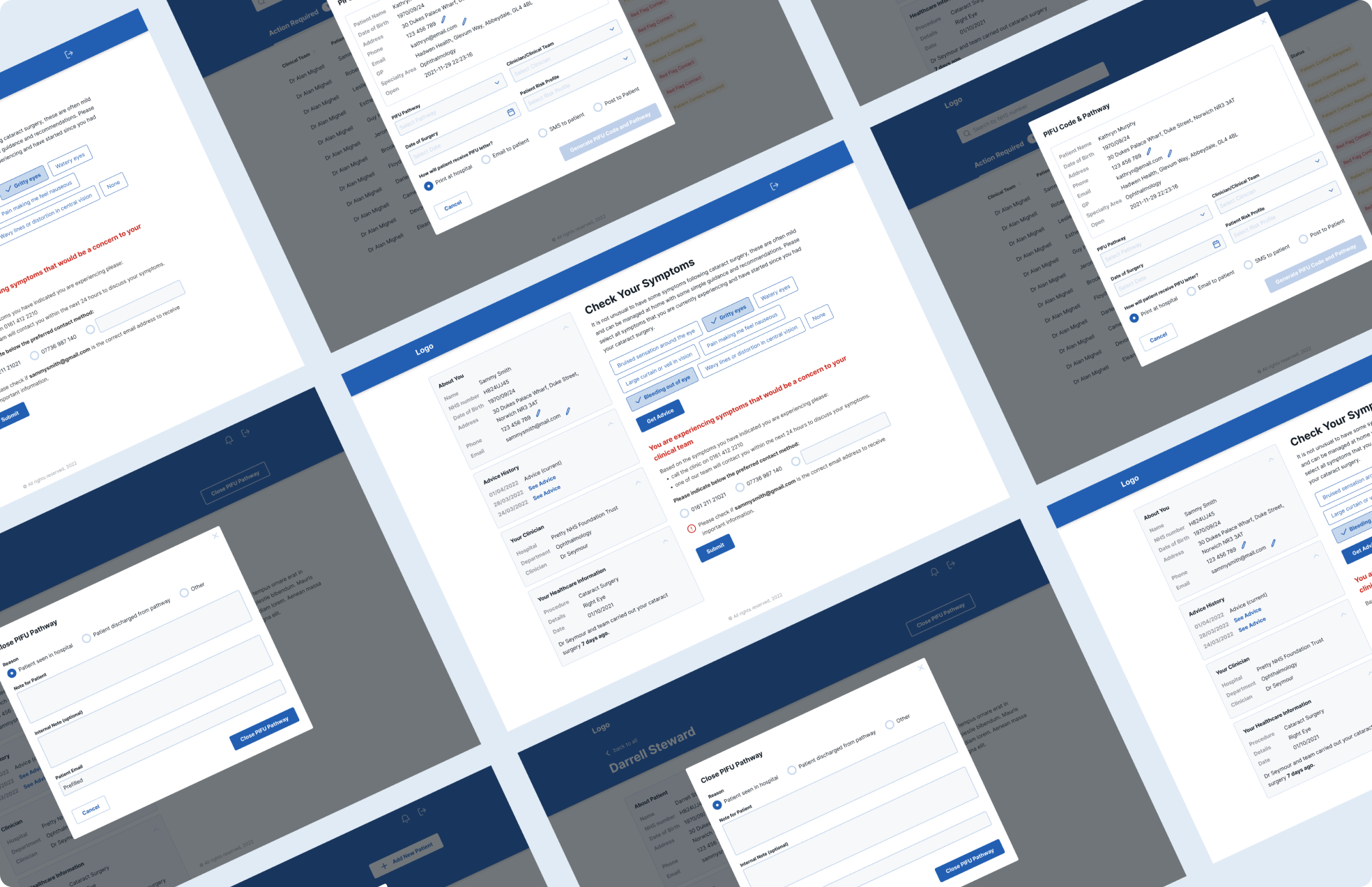
Customer location: The US ![]()